Transformer中最关键的有以下几个部分:
1、词嵌入(将文本转换为机器能“看得懂”的内容)
例如:我今天穿灰色的羊毛衫。转换为“我”,"今天”,"穿”,"灰色”,"的”,"羊毛衫”,"。”
在大模型内部有一个大字典,每个中文、字母或者符号,都可能唯一对应一个序号。例如123号是“你好”,654号是“!”,9128号是“abandon”。
因为这个字典设计的不同,相同的一个文字或者单词,实现起来可能是不同长度的,例如“羊毛衫”可能在模型A中就是214号,但是在模型B中,就是498号“羊毛”,2191号“衫”组成。这也就有了在模型A中羊毛衫是1个Token,但是在模型B中就是2个了。
但是实际上比上面说的要稍微复杂一点,每个输入的词首先会被分词器Tokenier转换为ID,然后将ID转换为词向量的形式,例如Ei=[0.621,-0.1297,-0.3449,0.3147]。这个词向量并非随机数字的堆砌,而是模型在海量文本学习后,为每个Token生成的一个高维空间坐标。在这个空间里,意思相近的词,它们的坐标也倾向于彼此靠近。例如,“羊毛衫”和“毛衣”的向量在空间中的距离,会比“羊毛衫”和“电脑”的距离近得多。这种将离散的ID转换为连续、稠密的向量表示,是模型能够理解和处理语言含义的基础。
2、位置编码(为了告诉机器不同词之间的前后关系)
例如我们输入我今天穿灰色的羊毛衫。希望机器理解的为“我”->"今天”->"穿”->"灰色”->"的”->"羊毛衫”->"。”
而不是“我”,"今天”,"穿”,"灰色”,"的”,"羊毛衫”,"。”这样的集合,为什么?对于相同一个集合,排列组合后的意思就可能会有天差地别的区别:
就像是需要让机器能够区分:我今天穿灰色的羊毛衫,而不是羊毛衫穿今天灰色的我。
那么怎么办呢?很容易想到的是你可以给每个Token上添加一个序号,例如:
[“我”,“0”],
["今天”,“1”],
["穿”,“2”],
["灰色”,“3”],
["的”,“4”],
["羊毛衫”,“5”],
["。”,“6”]。
在Transformer中,确实也有类似的思想,但是不同的是,存在一些问题:
a)词意不共享。如果示例改为:我今天穿灰色的羊毛衫。但是明天我想穿黑色的运动服。[“我”,“0”]和[“我”,“9”]就成了两个全新Token,模型会把它们当作陌生词来学,无法认识其实都是“我”,只是位置不同罢了。这就像把每个人的名字后面硬贴“房间号”,结果“张三1”和“张三2”被当成两个人。
b)长度有限。例如你每天都在学习100以内的加减法,但是考试的时候,问你101-1=多少,这个时候你就懵逼了,你并不知道101和0~100的关系。
c)离散编码会让模型训练爆炸。例如你正在设计一个逼近拟合程序,希望通过数据拟合y=2x,通过一系列拟合之后,得到y_now=1.999x,此时输入的数据为(1000,2000),通过你的y_now=1.999x=1999,误差E=1999-2000=-1,假设更新系数并不小,此时可能你的y_now会被更新为1.3x,这就导致了不收敛。
d)占用空间。在实际的Transformer中,词和位置是“相加”的,这样可以节省空间,但模型也能正确区分位置和词。目前这种离散数字的形式,明显大多数都是大于词向量的,肯定没法简单相加,因为会导致只能看到位置(大的数字),看不到词的信息(小的数字)。
解决方案很简单:
将位置映射到一个小的范围,例如-1~1到范围。但这会引入新的问题,如果输入10个字,那么第2个和第3个字的距离就是0.1。如果输入100个数,第2个字和第三个字的距离就变成了0.01。步长不一致,没法方便的分析“相邻或者不相邻”。
Transformer的作者Vaswani提出了一种天才的设计:用周期函数Sin和Cos来表示位置,
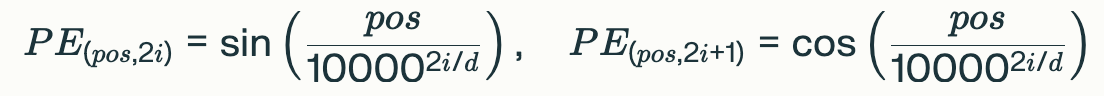
PE(位置,维度)是关于三角函数的函数,维度为偶数时使用Sin,奇数时使用Cos。维度越大,Sin或者Cos参数的分母越大,此时Cos或者Sin的波长就越长(函数值随着位置的变化就越慢)。
目前很多大模型使用了旋转位置RoPE编码,这个依赖于后面的知识,这里暂时不展开。
3、自注意力机制与多注意力机制
在很多时候,语言的真实意思并不是每个单词简单组成的,而是由上下文表示的。例如:
“it”:在“The cat drank the milk because it was hungry”中指猫,在“The milk was sweet, so it was drunk”中指牛奶。
“bank”:在“I went to the bank of the river”中指“河岸”,而“I deposited money in the bank”中指“银行”。
“苹果”:在“吃苹果”中指水果,在“苹果公司”中指公司。自注意力通过权重关联“吃”(与水果相关)或“公司”(与企业相关),解决歧义。
或者是:快迟到了,他还没走。与因为他体弱多病,最终不幸在昨天走了。这两处“走”的意思截然不同,那么怎么能够进行区分呢?
所以这里引入注意力机制:
自注意力机制简单的说,包括三部分:Q(Query 查询 我要找什么?)、K(Key 键 我是什么?)、V(Value 值 承载实质内容,详细的某个东西)。
就像是你在衣柜里面寻找灰色的羊毛衫(Query查询),有蓝色的羊毛衫、黑色的运动服、白色的袜子、灰色的羊毛衫(每个携带有自己的Key)。通过Q矩阵和K矩阵的点乘,就能得到相似度矩阵。根据相似度分数最大的结果,返回对应的V(灰色的羊毛衫)。
通过这种方法,对每个词向量进行询问和回答,就能够得到不同的词向量之间的关联,将相似的内容进行合并,也就是所谓的添加上了上下文。
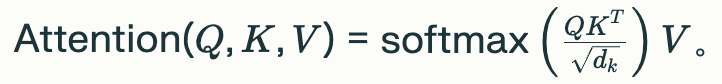
可以看到公式右侧,Q与K矩阵点乘,得到“相似度矩阵”。softmax是归一化,将数据范围控制在0~1,并且总和为1(所有概率子集的和为100%)。
例如Q和K点乘的结果为(1,1,2,2,1,3),经Softmax函数归一化后为(0.0632, 0.0632, 0.1718, 0.1718, 0.0632, 0.4669),总和为1。

除以根号dk是为了防止Q与K点乘的结果过大,导致softmax输入的极端化,使得归一化出来结果差异过大。
想象softmax像"软化"的独热编码:输入分数如温度,温度过高(未缩放)像沸腾,只剩最高峰(梯度死区);除dkdk像调温器,保持温和分布,所有位置都有梯度反馈,就像均衡加热让整个锅均匀煮熟。
我们前面讲到,Q与K的计算得到相似度矩阵,然后矩阵乘V矩阵,得到0.999个灰色的羊毛衫,0.001个蓝色的羊毛衫,0个黑色的运动服,0个白色的袜子。
